记录一次RAID5 + BTRFS的文件损坏与恢复
1. 前言
上个月的时候我写了一篇《在飞牛fnOS上手动进行文件完整性校验》,当时纯粹是当作了解学习一个新的知识点并顺手做一个记录,但没有想到这么快就派上了用场,因为在不到一个月之后的6月9号,我在自己nas的raid5 + btrfs的存储空间进行btrfs scrub的时候,竟然报了6000多个uncorrectable errors(截图的时候是5000多个,等扫描完了达到6000多个)。
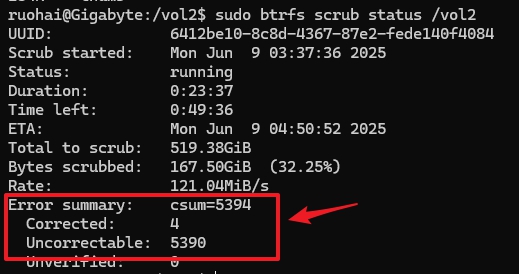
这可如何是好啊!虽然折腾nas折腾linux也有小2年,但这应该是我第一次发现了文件损坏的情况。以前肯定也有,因为我用的硬盘都是二手拆机硬盘,质量参差不齐,只要系统(黑群或者fnos)没有报异常,就当没有。
不过遇事不能慌,要慢慢理顺逻辑,搞清楚这6000多个无法修正的错误代表什么意思,然后想办法修复它们。
在写下这篇文章的时候,我已经完成了这次文件损坏的恢复,因为万幸我有一个备份nas,最后从备份中恢复了损坏的300多个文件。
这篇文章简单做个记录,希望对你也有一些帮助。
tips:要明确一点,btrfs scrub扫出来的uncorrectable errors就是无法修正的错误,没法通过mdadm raid进行恢复,因为mdadm是硬件冗余而不是备份,不是备份,不是备份。如果没有备份,那就没办法恢复了。
2. 事件回溯
我的NAS配置
我的nas的软硬件环境如下:
- 软件:系统是fnos,存储方案是mdadm + lvm + btrfs
- 硬件:基于intel h55主板diy的主机,有6个原生sata接口。一开始用其中5个sata口组建了5盘位raid5,后来换机箱,用了一块pcie转5 sata转接板实现了6+5一共11个sata接口,这个5盘位raid5阵列,2个盘插在原生sata口,3个盘插在转接的sata口。
中间发生了什么
- 在5月14日的时候执行
btrfs scrub提示no errors found,所以此时没有文件损坏。 - 在6月7号时更换了机箱,从普通机箱换成了8盘位nas机箱,更换完成后成功点亮系统无异常。
- 点亮系统后,对5盘位的raid5阵列进行了更换其中一块硬盘的操作,也就是【在web控制台停用一块硬盘 + raid5降级运行 + 添加一个新硬盘 + raid5阵列重建】,整个过程顺利完成,无异常报错。
- 对重建后的这个5盘位raid5阵列进行
btrfs scrub操作,出现大量的uncorrectable errors报错。 - 对这个raid5阵列进行
mdadm --check操作,验证完成后无报错无异常。 - fnos的web控制台中查看存储空间,显示
正常。(图片为示意图)
tips:不管是群晖还是fnos,在web控制台中显示的阵列是否健康或者正常,针对的都是用mdadm创建的这个raid是否健康,mdadm --check校验的内容是条带化数据与奇偶校验块是否一致。这个健康或者正常,无法代表底层文件系统(这里是btrfs)上的文件是否出现了静默损坏或一致性异常。
异常原因分析
根据以上回溯信息,大致可以判断,应该是更换机箱 + raid5换盘重建的过程中出现了问题,但无法确定具体是哪一步、哪一个硬件的问题。也许是pcie转sata口转接板有问题?也许是用拆机二手盘组raid5在重建的时候碰到坏道导致的文件损坏?也许是因为内存不带ecc?也许是新机箱的电气屏蔽不好?也许是老旧的atx电源质量太差稳定性不足?
但这些都不是当下的重点了,现在的重点是要想办法处理btrfs文件系统的6000多个errors。
3. 文件恢复
虽然btrfs scrub明确提示了有6000多个errors,但是没有明确给出重要信息:
- 有没有文件损坏
- 有多少个文件损坏
- 是哪些文件损坏
因为6000多个无法修复的错误可能只涉及几个文件,也可能涉及更多文件,具体取决于受损数据块属于哪些文件。
我有另一个冷备nas上有备份,但这个备份上一次同步已经是2个月之前,没法简单的直接还原。我需要一份准确的损坏的文件清单,然后在备份nas中找到这份清单上的文件进行恢复。
所以,这次文件恢复的最重要、最核心的任务就明确了:拿到损坏文件的清单。
tips:因为我的raid5阵列显示健康度clean没有问题,mdadm --check也没有报异常,所以我没有着急备份阵列(或者说备份阵列中的数据)。但我依然建议你如果碰到这种情况,优先进行备份。
方法一:查看内核日志(不推荐)
btrfs文件系统在进行scrub的过程中,碰到校验和错误,理论上异常信息中会包含对应的文件信息。
dmesg | grep -i btrfs
输出的日志信息大致如下:
[ 1081.234649] BTRFS info (device dm-1): scrub: started on devid 1
[ 1106.798652] BTRFS error (device dm-1): unable to fixup (regular) error at logical 3262971904
on dev /dev/mapper/trim_f8875261_e43f_4a86_9e9f_20b560e735c0-0 physical 4345102336
[ 1106.798720] BTRFS error (device dm-1): unable to fixup (regular) error at logical 3262971904
on dev /dev/mapper/trim_f8875261_e43f_4a86_9e9f_20b560e735c0-0 physical 4345102336
[ 1106.804440] BTRFS error (device dm-1): unable to fixup (regular) error at logical 3262906368
on dev /dev/mapper/trim_f8875261_e43f_4a86_9e9f_20b560e735c0-0 physical 4345036800
可以看到scrub start的标记,接着输出无法修复的错误所在的逻辑块编号和物理块的编号。
然后用以下命令查看对应逻辑块3262971904上的文件,我的raid5阵列在fnos中的挂载点是/vol2:
btrfs inspect-internal logical-resolve 3262971904 /vol2
tips:我实测这个方法并不可靠,显示的信息不全,容易遗漏文件。
方法二:扫描整个文件系统(推荐)
这个方法比较暴力,就是cat命令把存储空间中的每一个文件都读取一遍,如果文件损坏,在读取的时候就会报错,只需要记录出现报错的文件即可获取完整清单。
find /vol2 -type f -exec cat {} >/dev/null 2>>/path/to/damaged_files.log \;
也可以用rsync命令,在全量读取文件的同时也完成了文件的备份(推荐这个方法)
rsync -avh --progress /vol2 /backup/destination 2>>/path/to/backup_errors.log
tips:我用的rsync命令,既完成了文件系统的遍历,也完成了文件的备份,一举两得。
这里以rsync为例,在读取到损坏的文件时,会出现异常错误日志,示例如下:
sending incremental file list
Photo/2012/10/20121004_135000_E6BE7593.jpg
32,768 36% 132.78kB/s 0:00:00
90,137 100% 365.25kB/s 0:00:00 (xfr#3, ir-chk=1092/14468)
rsync: [sender] read errors mapping "/vol2/1000/Archive/Photo/2012/10/20121004_135000_E6BE7593.jpg": Input/output error (5)
Photo/2012/11/20121121_022631_D8537437.jpg
21,846 100% 87.43kB/s 0:00:00
21,846 100% 87.43kB/s 0:00:00 (xfr#4, ir-chk=1062/14833)
rsync: [sender] read errors mapping "/vol2/1000/Archive/Photo/2012/11/20121121_022631_D8537437.jpg": Input/output error (5)
WARNING: Photo/2012/10/20121004_135000_E6BE7593.jpg failed verification -- update discarded (will try again).
Photo/2013/02/20130207_213239_6CD7224C.jpg
在日志中可以看到错误原因Input/output error,也可以看到完整的文件路径/vol2/1000/Archive/Photo/2012/10/20121004_135000_E6BE7593.jpg。
等rsync完成同步以后,用ai写个脚本提取错误日志中的损坏文件信息,就可以拿到最终的损坏文件清单了。
🎉
4. nas使用心得和建议
- 文件系统请选btrfs而不是ext4
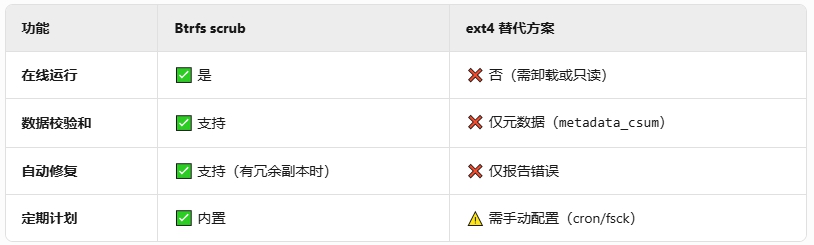
- 如果是群晖,请一定要开启【文件一致性校验】
- 如果是fnos,fnos目前web控制台中没有【文件一致性校验】功能的入口,需要手动执行
btrfs scrub - 文件一致性校验(btrfs scrub)执行的频率,请根据三个维度来调整:1-硬件稳定性,2-硬盘健康度,3-数据重要性。因为
btrfs scrub会全量读取一遍硬盘上的数据,对硬盘的io有一定压力,请根据自己的情况,酌情调整scrub的频率,短则一周一次,长则1~6个月一次。 - raid是硬件冗余而不是备份,不是备份,不是备份。如果文件很重要,请备份。如果做不到3-2-1备份,请至少做一个备份
最后,希望你的nas永远运行稳定,希望你的数据永远安全无损坏。
🎉
喝杯奶茶
